Explore Natural Language multilingual models
 laurent b
laurent b
Description: Learn how to create custom Natural Language models for text classification and word tagging using multilingual, transformer-based embeddings. We’ll show you how to train with less data and support up to 27 different languages across three scripts. Find out how to use these embeddings to fine-tune complex models trained in PyTorch and TensorFlow. For more on Natural Language, check out "Make apps smarter with Natural Language” from WWDC20.
Topics
- Evolution of NLP
- NL understanding
- Multilingual embeddings
- Advanced applications
Evolution of NLP Models
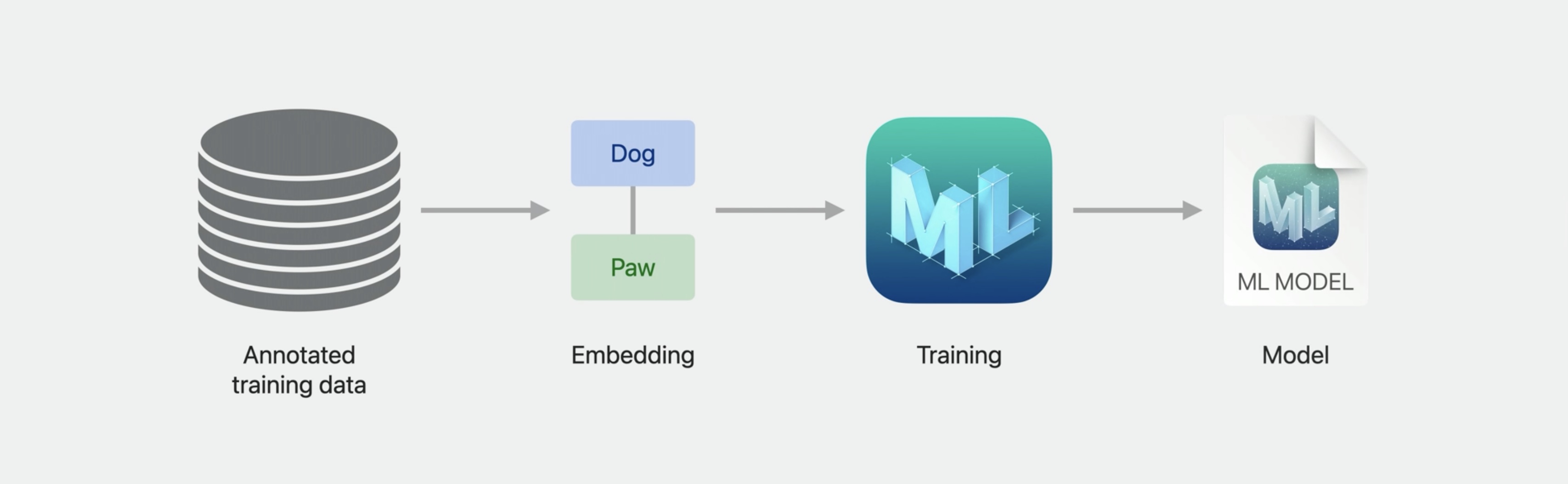
Schematically, NLP models generally have a similar flow. They start off with text data, then have an input layer that converts it to a numerical feature representation, upon which a machine learning model can act, and that produces some output. The most obvious examples of this from previous years are the Create ML models that are supported for text classification and word tagging. The development of NLP as a field can be traced fairly closely just by the development of increasingly sophisticated versions of the input layers.
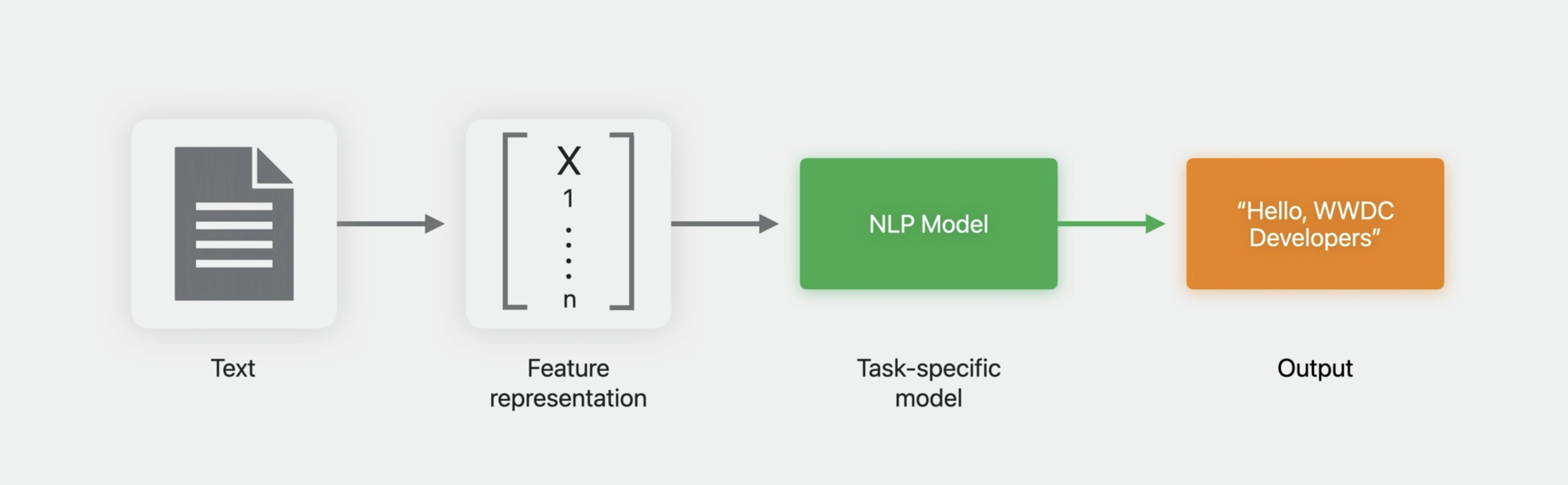
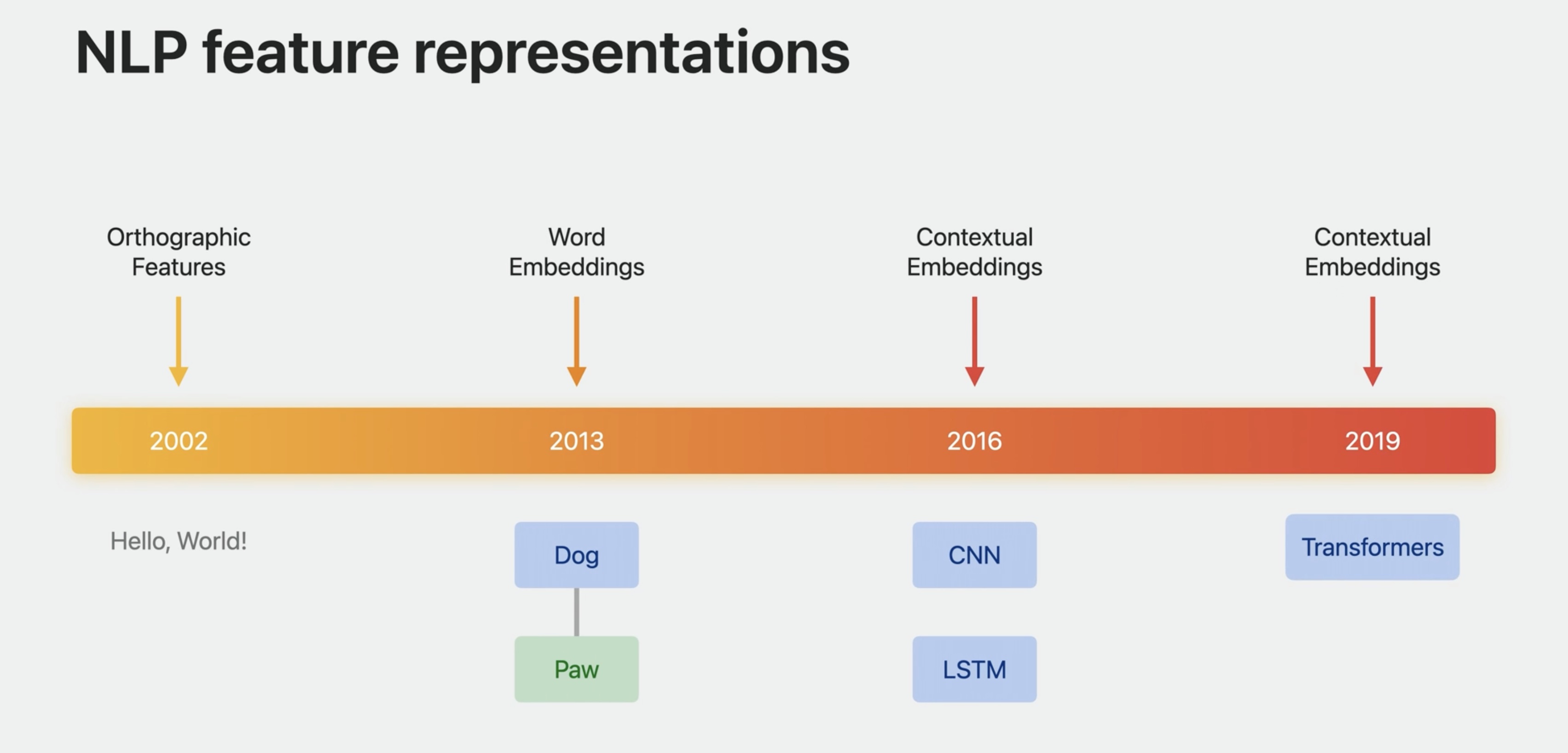
Ten or twenty years ago, these were simple orthographic features. Then about a decade ago, things moved to the use of static word embeddings, such as Word2Vec and GloVe. Then to contextual word embeddings based on neural network models, such as CNNs and LSTMs. And more recently, transformer-based language models.
Embeddings
I should say a few words about what an embedding is. In the simplest form, it’s just a map from words in a language to vectors in some abstract vector space, but trained as a machine learning model such that words with similar meaning are close together in vector space. This allows it to incorporate linguistic knowledge.

Static Embeddings
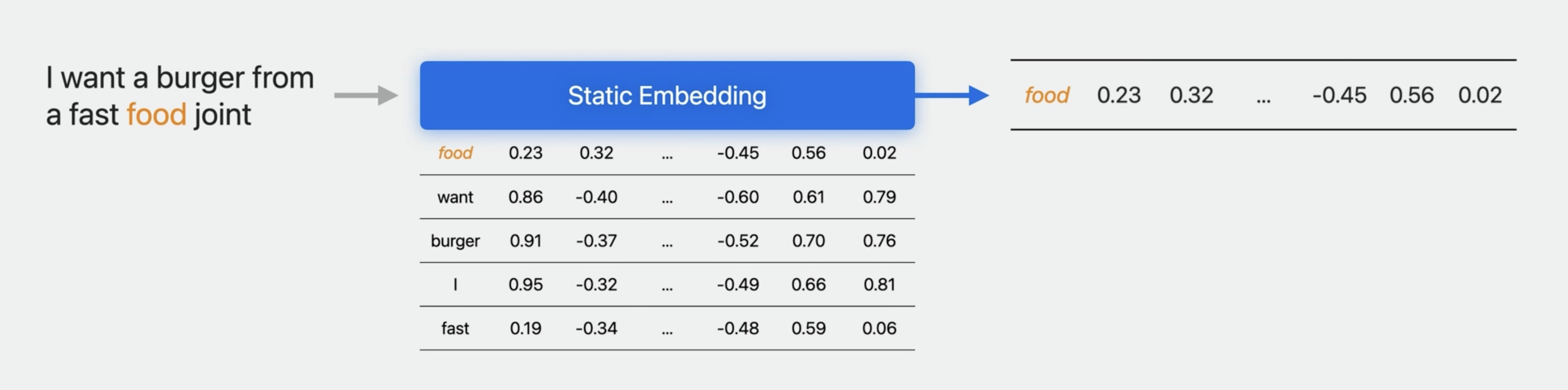
Static embeddings are just a simple map from words to vectors. Pass in a word, the model looks it up in a table and provides a vector. These are trained such that words with similar meaning are close together in vector space.
Contextual embeddings
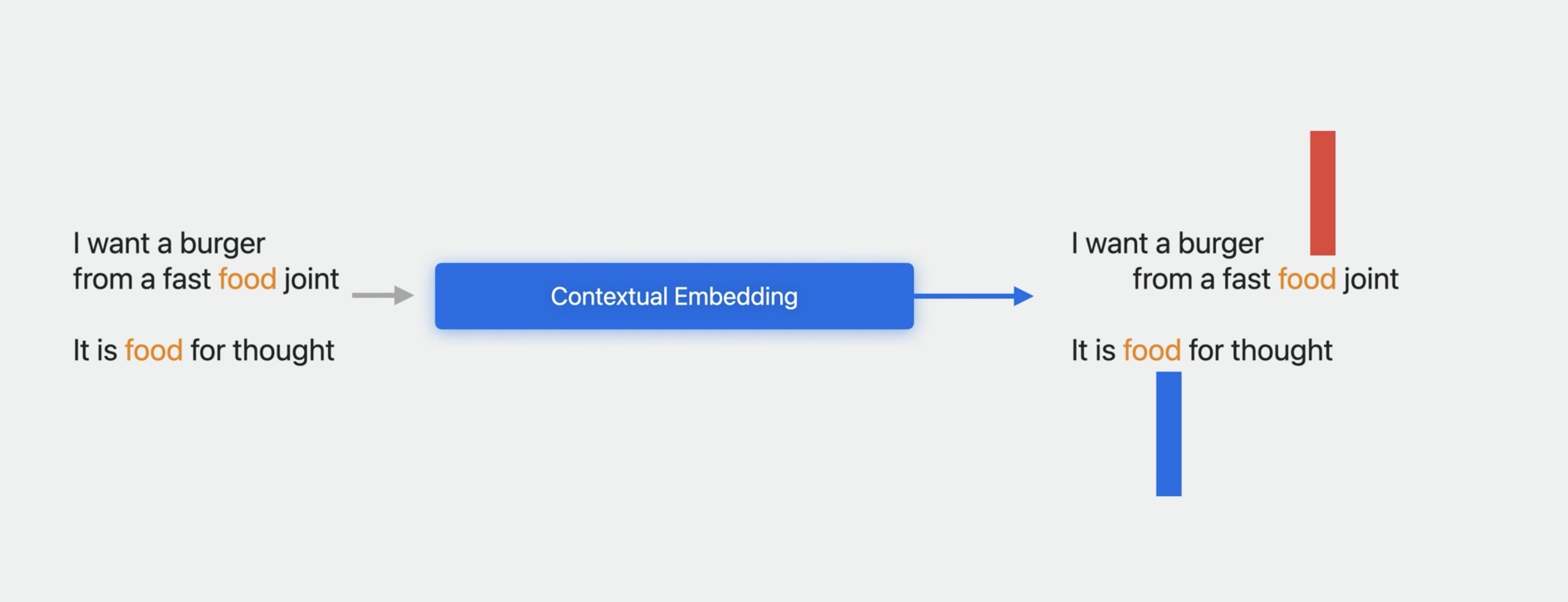
This is quite useful for understanding individual words. More sophisticated embeddings are dynamic and contextual such that each word in a sentence is mapped to a different vector depending on its use in the sentence. For example, “food” in “fast food joint” has a different meaning than “food” in “food for thought,” so they will get different embedding vectors.
Now, the point of having a powerful embedding as an input layer is to allow for transfer learning. The embedding is trained on large amounts of data and encapsulates general knowledge of the language, which can be transferred to your specific task without requiring huge amounts of task-specific training data.
ELMo models
Currently, Create ML supports embeddings of this sort using ELMo models. These models are based on LSTMs whose outputs are combined to produce the embedding vector.
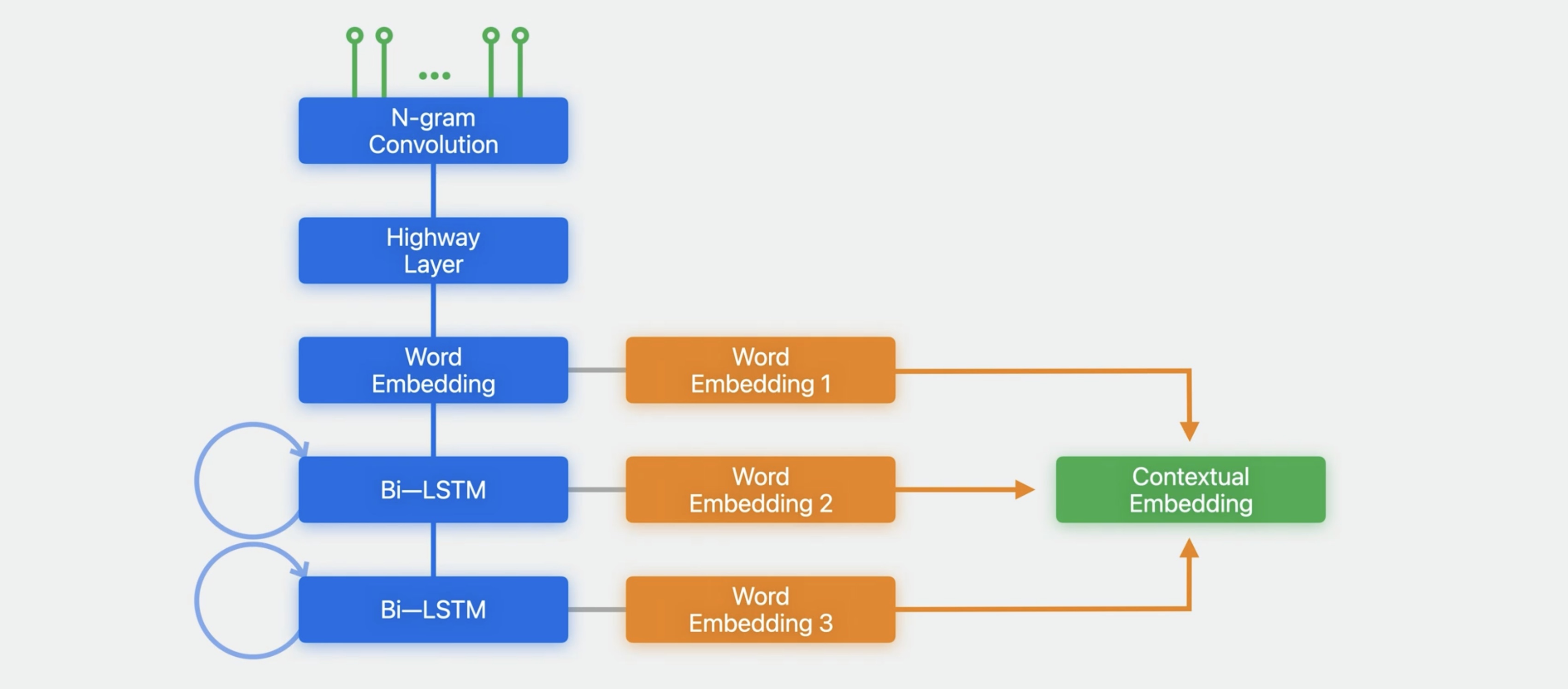
These can be used via Create ML for training classification and tagging models.
NLP Models Recap
Now, let me discuss the models that have been supported so far. These were discussed in great detail in previous sessions in 2019 and 2020, so I’ll just describe them briefly here.
Natural Language supports model training using Create ML that generally follows the pattern we’ve seen for NLP models.
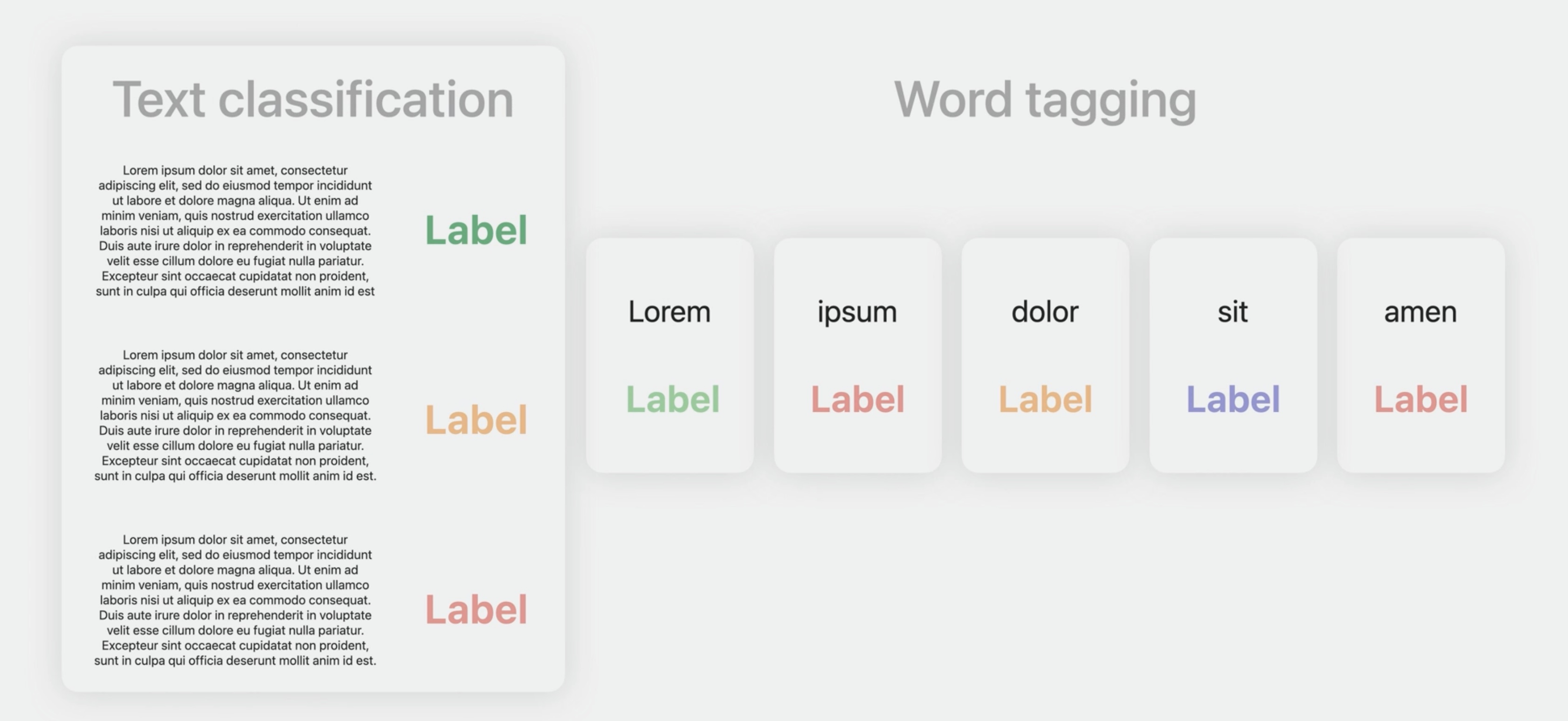
This involves models for two different tasks: text classification and word tagging.
Classification and tagging
In text classification, the output describes the input text using one of a set of classes. For example, it might be a topic or a sentiment. And in word tagging, the output puts a label on each word in the input text, for example, a part of speech or a role label.
Create ML models
And the supported Create ML models have generally followed the evolution of the NLP field, starting with maxent and CRF-based models, then adding support for static word embeddings, and then dynamic word embeddings for Create ML models using ELMo embeddings.
And you can view the detail on this in previous sessions, “Advances in Natural Language Framework” - WWDC2019 and “Make Apps Smarter with Natural Language” - WWDC 2020.
# Multilingual Embeddings
BERT embeddings
Now let me turn to what's new this year in Natural Language. I’m happy to say that we now provide transformer-based contextual embeddings. Specifically, these are BERT embeddings. That just stands for Bidirectional Encoder Representations from Transformers. These are embedding models that are trained on large amounts of text using a masked language model style of training.
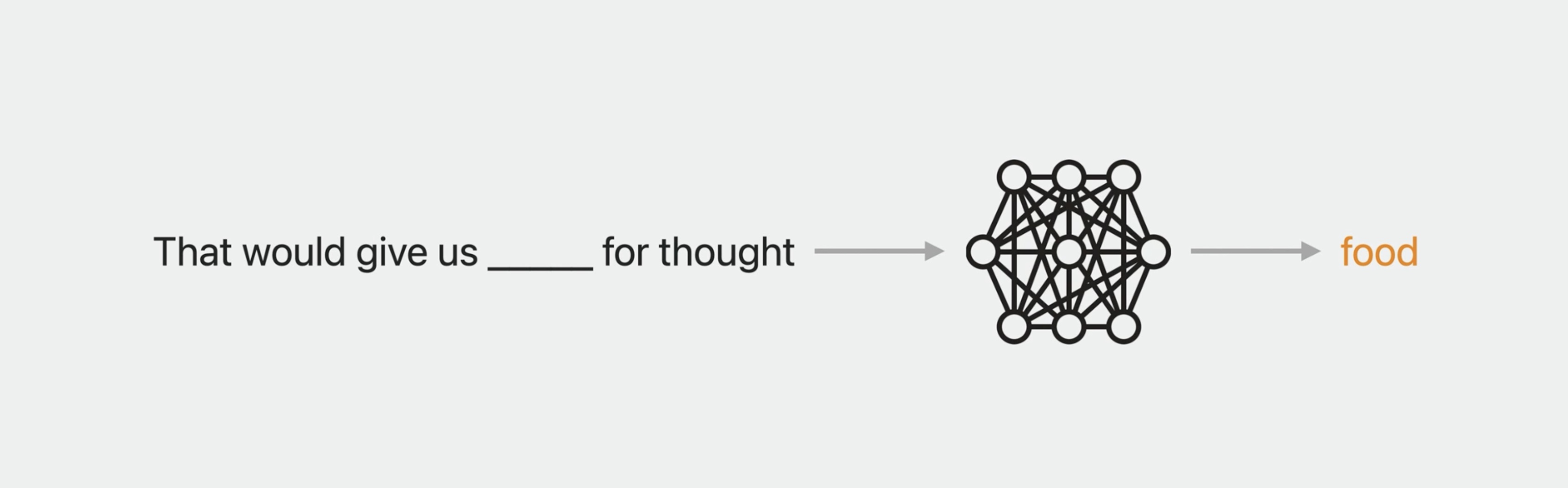
This means that the model is given a sentence with one word masked out and asked to suggest the word, for example, “food” in “food for thought,” and trained to do better and better at this.
Transformers
Transformers at their heart are based on what’s called an attention mechanism, specifically, multi-headed self-attention, which allows the model to take into account different portions of the text with different weights, in multiple different ways at once.
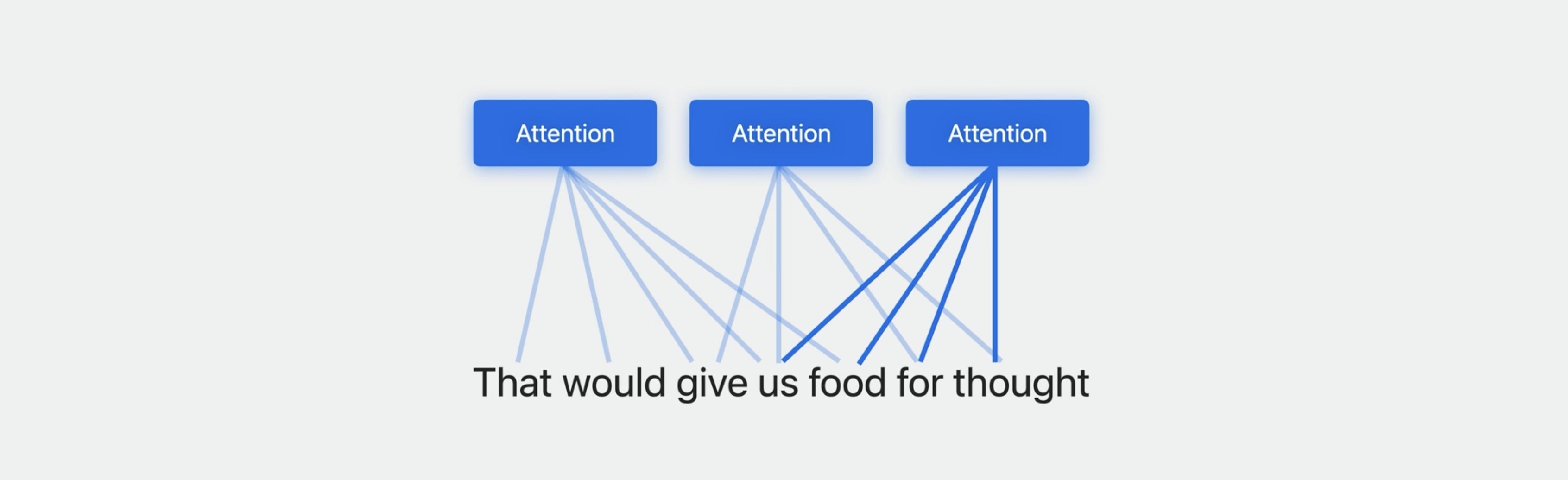
The multi-headed self-attention mechanism is wrapped up with multiple other layers, then repeated several times, which altogether provides a powerful and flexible model that can take advantage of large amounts of textual data. So much so in fact that it can be trained on multiple languages at once, leading to a multilingual model.
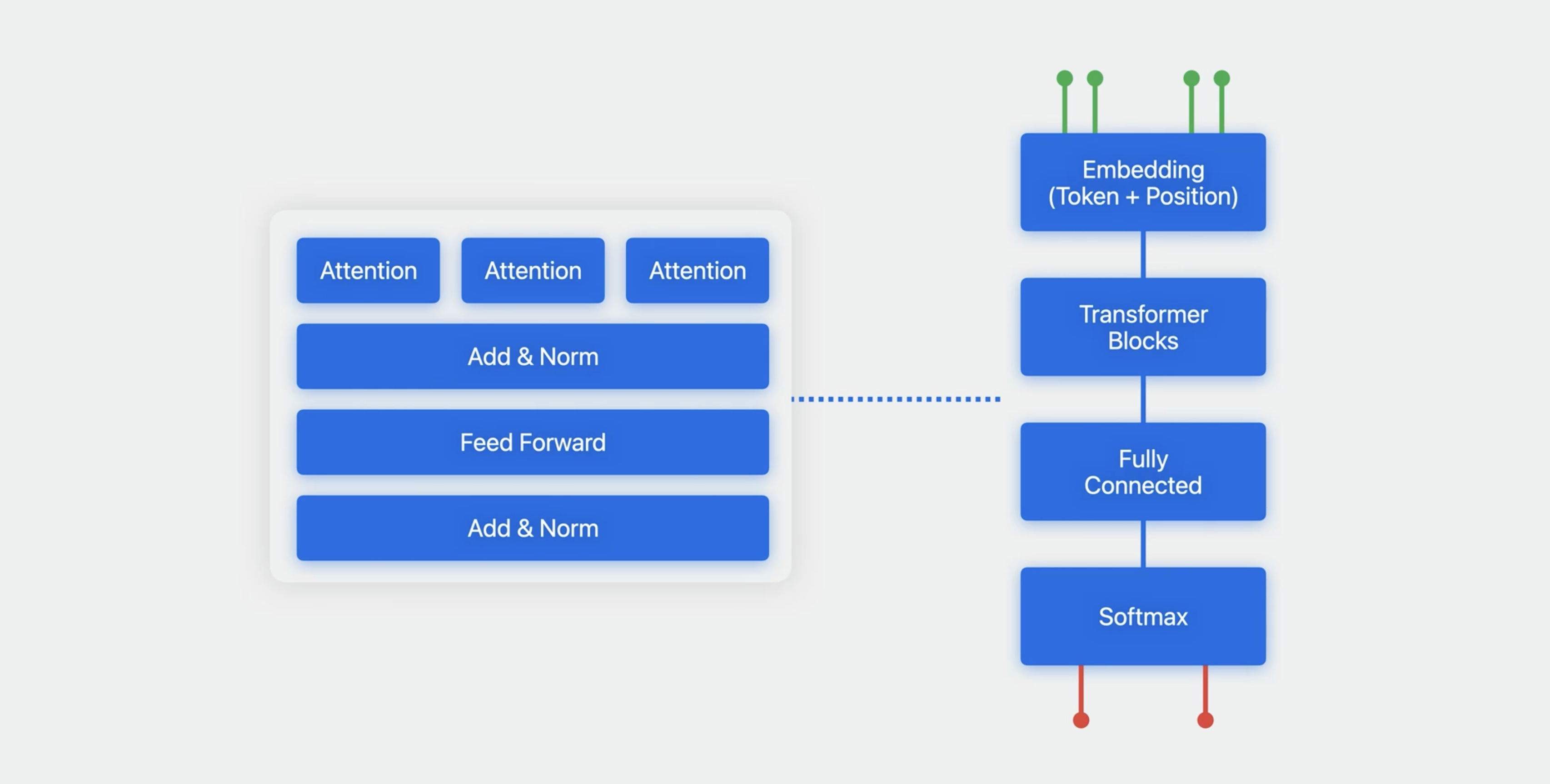
Multilingual BERT embeddings
- Each model is trained on data from multiple languages
- One model per group of related scripts
- Takes advantage of similarities between languages
This has several advantages. It makes it possible to support many languages immediately and even multiple languages at once. But even more than that, because of similarities between languages, there's some synergy such that data for one language helps with others.

Supported scripts
- Latin script-20 languages
- Cyrillic script-4 languages
- CJK-Chinese, Japanese, Korean
So we’ve gone immediately to supporting 27 different languages across a wide variety of language families. This is done with three separate models, one each for groups of languages that share related writing systems. So there's one model for Latin-script languages, one for languages that use Cyrillic, and one for Chinese, Japanese, and Korean.
These embedding models fit right in with the Create ML training we discussed earlier, serving as an input encoding layer. This is a powerful encoding for many different models. In addition though, the data that you use for training doesn’t have to all be in a single language.
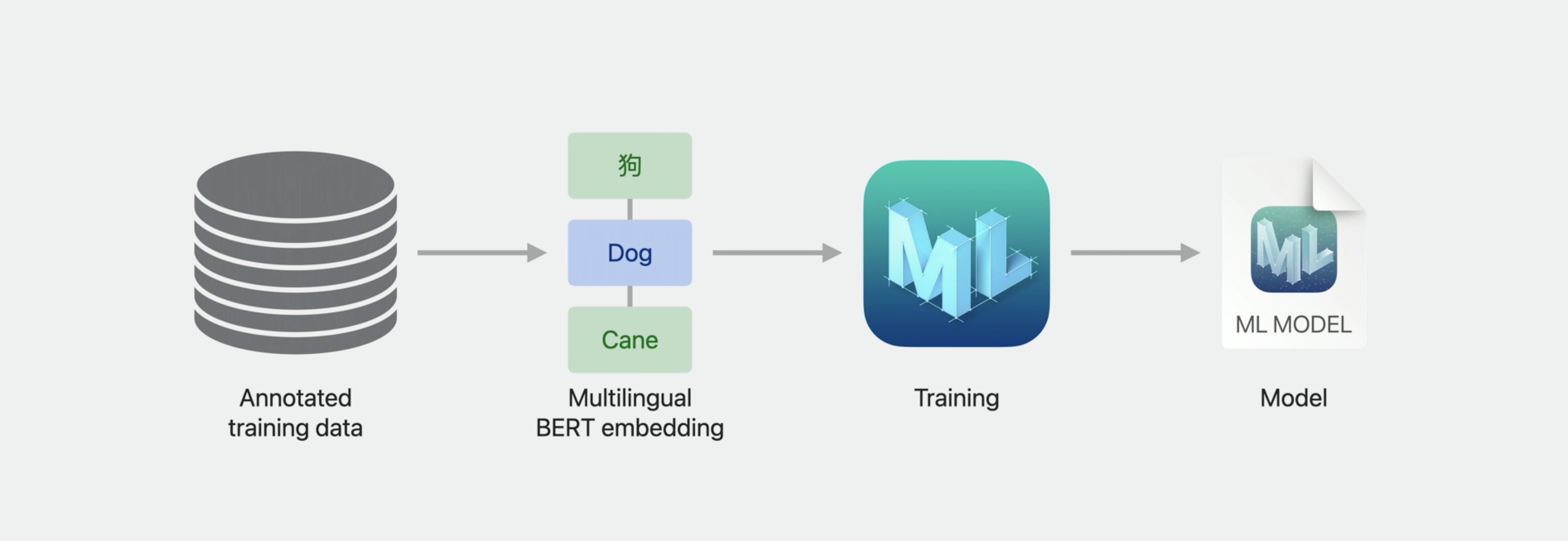
Classifying messages
Let me show you how this works with an example. Suppose you're writing a messaging app and want to aid users by automatically classifying the messages that they receive. Suppose you want to divide them into three categories: personal messages, such as you might receive from your friends, business messages, such as you might receive from your colleagues, and commercial messages, such as you might receive from businesses you interact with.
But users might receive messages in many different languages, and you want to handle that. For this example, I’ve assembled some training data in multiple languages, English, Italian, German, and Spanish. I used json format, but you could also use directories or CSV.
//Training data
{"text": "Let's schedule a meeting for tomorrow morning.", "label": "Business"},
{"text": "Visita il nostro sito per offerte speciali.", "label": "Commercial"},
{"text": "Willst du mit mir spazieren gehen?", "label": "Personal"},
...
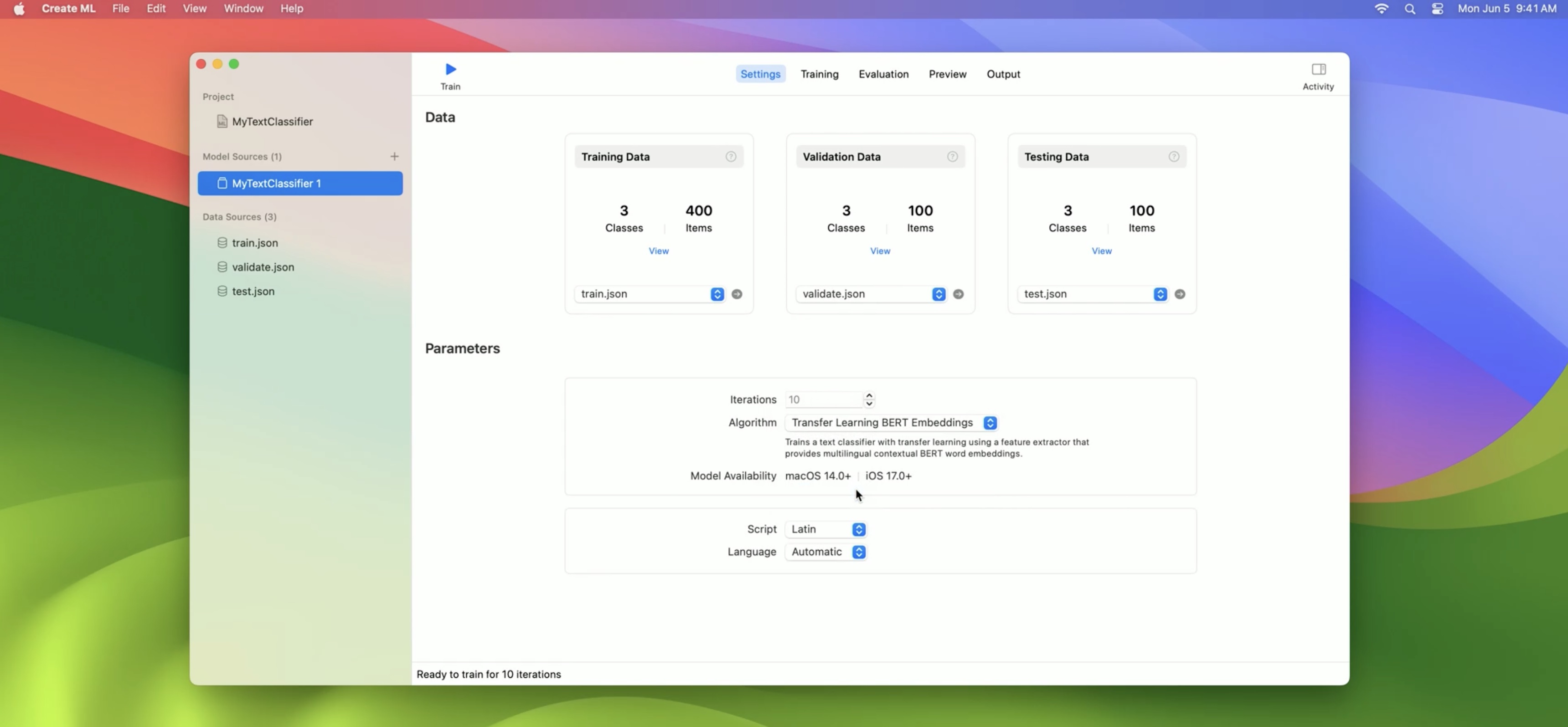
To train our model, we go into the Create ML app and create a project. Then we need to select our training data.
I’ve also prepared validation data and test data to go along with it.
Then we need to choose our algorithm, and we have a new choice here: the BERT embeddings.
Once we’ve chosen those, we can choose the script. Since these are Latin-script languages, I’ll leave it on Latin. If we were using a single language, we would have the option of specifying it here, but this is multilingual, so we’ll just leave it on automatic.
Then all we need to do is press Train, and model training will start. The most time-consuming part of the training is applying these powerful embeddings to the text. Then the model trains fairly quickly to a high degree of accuracy.
At that point, we can try it out on some example messages.
In English… Or Spanish.
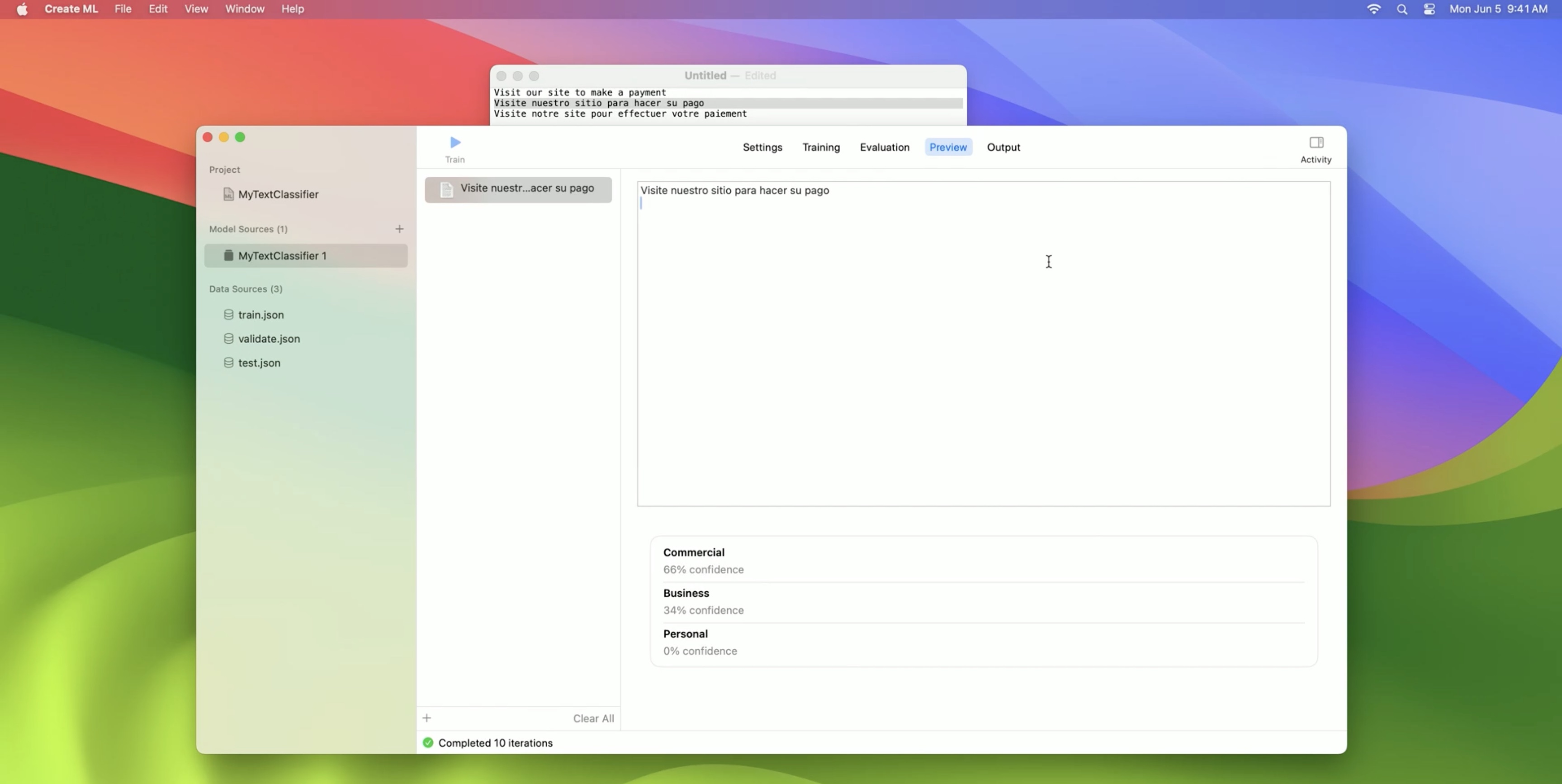
And the model is pretty confident that these are commercial messages. As an example of the synergies that are possible, this model hasn’t been trained on French, but it can still classify some French text as well.
I do recommend though that you use training data for each of the languages you are interested in.
NLContextualEmbedding APIs
- Find embeddings for specific languages or scripts
- Obtain metadata for embedding
- Supported languages and scripts, revision, dimension, identifier
- Find embedding by identifier
Now, so far we’ve just been working with Create ML, but it’s also possible to work with these embeddings using the Natural Language framework with a new class called NLContextualEmbedding. This allows you to identify the embedding model you want and find out some of its properties.
You can look for an embedding model in a number of different ways, for example, by language or by script. Once you have such a model, you can get properties such as the dimensionality of the vectors. Also, each model has an identifier, which is just a string that uniquely identifies the model. For example, when you start working with a model, you might locate it by language, but later on you would want to make sure that you're using the exact same model, and the identifier will allow you to do this.
// Obtain embedding object by language
guard let embedding = NLContextualEmbedding(language: .english) else { return }
// Obtain embedding object by script
guard let embedding = NLContextualEmbedding(script: .latin) else { return }
// Determine its dimensionality
let dimension = embedding.dimension
// Make a note of its identifier to use to retrieve it later
let modelIdentifier = embedding.modelIdentifier
Embedding models contained in assets that are delivered on demand
- Use asset APIs
- Create embedding object
- Check if assets are present
- Request assets if not
One thing to keep in mind is that, like many other Natural Language features, these embedding models rely on assets that are downloaded as needed. NLContextualEmbedding provides some APIs to give you additional control over this, for example, to request download before use. You can ask whether a given embedding model currently has assets available on device, and if not put in a request, which will result in their being downloaded.
if (!embedding.hasAvailableAssets) {
embedding. requestAssets { result, error in
// Handle result
}
}
Advanced Applications
Now, some of you may be saying, I have some models that I don’t train using Create ML, but instead I train using PyTorch or TensorFlow. Can I still use these new BERT embeddings? Yes, you can.
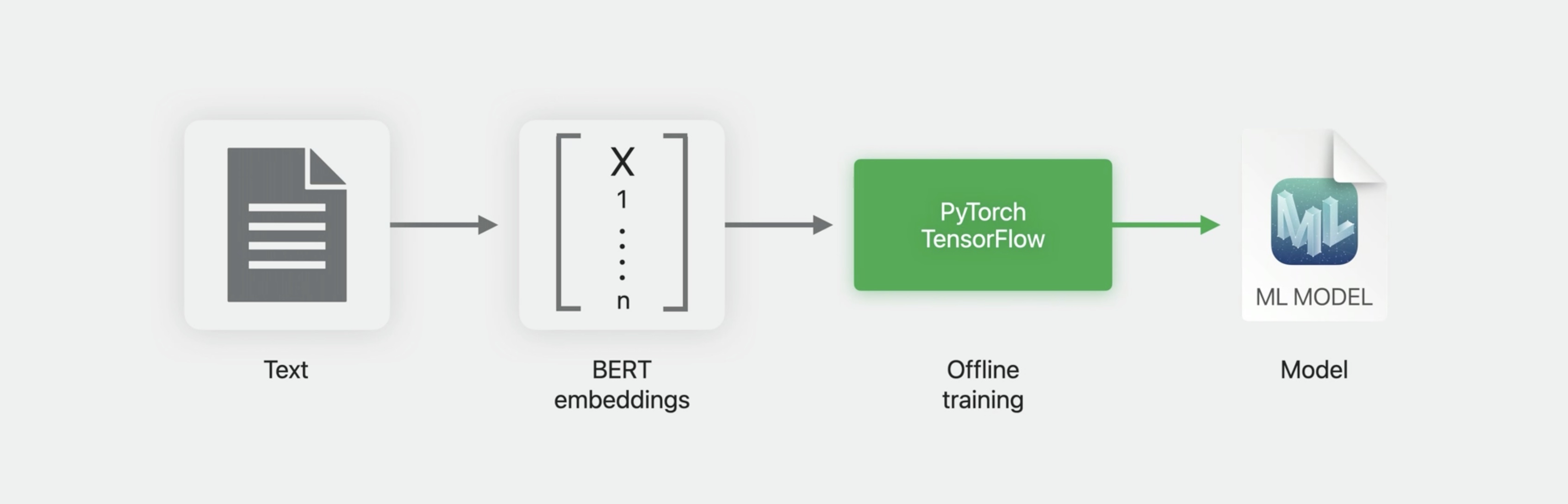
## Model training We provide these pre-trained multilingual embedding models that are available to you, that you can use as an input layer to just about any model you want to train.
Here’s how that would work. On your macOS device, you would use NLContextualEmbedding to get the embedding vectors for your training data. You would then feed these as input to your training using PyTorch or TensorFlow and convert the result to a Core ML model using Core ML tools.
Inference with embeddings
Then at inference time on device, you would use NLContextualEmbedding to get the embedding vectors for your input data, pass them into your Core ML model to get the output.
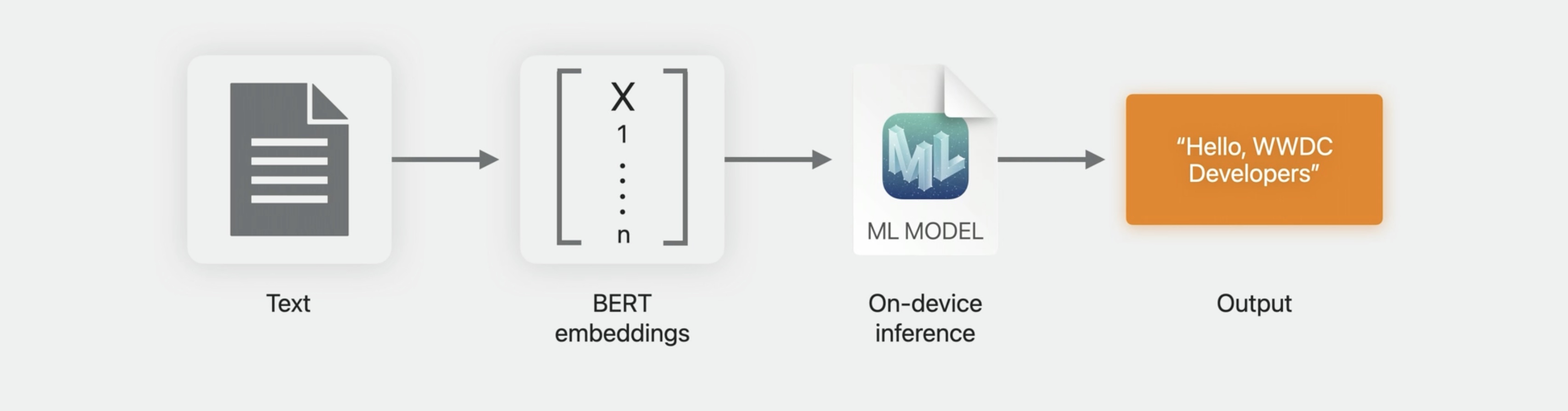
To support this, there are additional NLContextualEmbedding APIs that allow you to load a model, apply it to a piece of text, and get the resulting embedding vectors.
NLContextualEmbedding APIs
- Load model and apply to text
- Obtain embedding vectors as a result object
- Enumerate over embedding vectors
If you remember the model identifier from earlier, you can use that to retrieve the same model that you used for training. You can then apply the model to a piece of text, giving an NLContextualEmbeddingResult object. Once you have this object, you can then use it to iterate over the embedding vectors.
// Obtain embedding object
guard let embedding = NLContextualEmbedding(modelIdentifier: modelIdentifier)
else { return }
// Apply embedding to an example sentence
let string = "This is an example sentence."
guard let result = try? embedding.embeddingResult(for: string, language: .english)
else { return }
// Get the individual embedding vectors for each token in the string
result.enumerateTokenVectors(in: string.startIndex..<string.endIndex) {
(tokenVector, tokenRange) -> Bool in
return true
}
Adapting a model
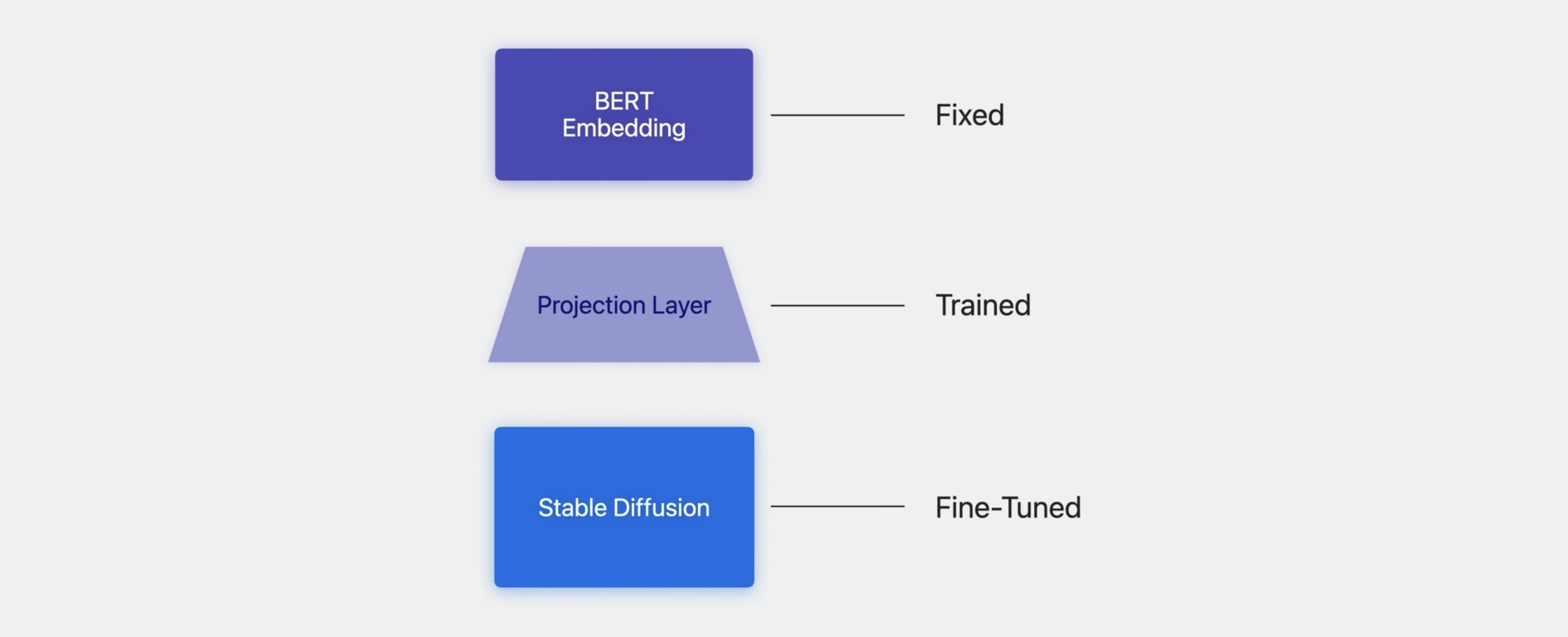
Now, to give you just a taste of what's possible with this, we prepared a simple example model. We started with an existing English-language Stable Diffusion model, then used some multilingual data to fine-tune it to use the new BERT embeddings as an input layer, taking those as fixed, and also training a simple linear projection layer to convert dimensionalities. The result then is a Stable Diffusion model that takes multilingual input.
Here are some examples of output from the model. If I pass in some English text, for example, “A path through a garden full of pink flowers,” the model leads us down a path into a garden full of pink flowers.

But also, if I translate the same sentence into French, Spanish, Italian, and German, the model produces images of paths and gardens full of pink flowers for each one.

Let me take a slightly more complicated example. “A road in front of trees and mountains under a cloudy sky.” Here’s some output from the model, with road, trees, mountains, and clouds. But likewise, I can translate the same sentence into French, Spanish, Italian, and German, or any of a number of other languages, and for each one get an image of road, trees, mountains, and clouds.

Wrap Up
- Train models using Create ML
- Use the new multilingual BERT embeddings
- Use BERT embeddings with your own models
You can use Create ML to easily train models for text classification or word tagging tasks, and the new multilingual BERT embedding models provide a powerful input encoding layer for this purpose. These models can be single-language or multilingual. You can also use the BERT embeddings as input layers for whatever model you want to train with PyTorch or TensorFlow.
Check out also
Discover machine learning enhancements in Create ML - WWDC23
Make apps smarter with Natural Language - WWDC20
Advances in Natural Language Framework - WWDC19
 Twitter
Twitter
 GitHub
GitHub
 iosdev.space
iosdev.space