Explore 3D body pose and person segmentation in Vision
 Rakesh Neela
Rakesh Neela
Description: Discover how to build person-centric features with Vision. Learn how to detect human body poses and measure individual joint locations in 3D space. We'll also show you how to take advantage of person segmentation APIs to distinguish and segment up to four individuals in an image. To learn more about the latest features in Vision, check out “Detect animal poses in Vision” from WWDC23.
Speaker: Andrew Rauh, Software Engineer
Human Body Pose in Vision
Previous Version
- In the initial version of Vision framework, body pose detection uses 2D coordinate system to locate and track the positions of body parts.
- It specifically uses x and y coordinates for detecting body part in the image or video.
See more in the session "Detect Body and Handpose with Vision" from WWDC20.
Human Body Pose in 3D
- New Vision framework expands and supports detecting human body in 3D with VNDetectHumanBodyPose3DRequest.
- This 3D request can detect 17 joints. These joints can be accessed by joint names or can be used as joint group name.
- The position of 3D joint is captured in meters from the relative to the image captured. This relative position can be defined as root joint.
- For example, when there are multiple persons present in real world, initial version will detect the most prominent person in the frame as a root joint.

VNHumanBodyPose3DObservation.JointName
- The 3D human body pose is being demonstrated with skeleton structure with different joint groups.
- Namely head, torso, left arm, right arm, left leg and right leg group names. (VNHumanBodyPose3DObservation.JointsGroupName)
.head group
- .centerHead - A joint name that represents the center of the head.
- .topHead - A joint name that represents the top of the head.

- .topHead - A joint name that represents the top of the head.
.torso group
- .leftShoulder - A joint name that represents the left shoulder.
- .centertShoulder - A joint name that represents the point between the shoulders.
- .rightShoulder - A joint name that represents the right shoulder.
- .spine - A joint name that represents the spine.
- .root - A joint name that represents the point between the left hip and right hip.
- .leftHip - A joint name that represents the left hip.
- .rightHip - A joint name that represents the right hip.

.leftArm group
- .leftWrist - A joint name that represents the left wrist.
- .leftShoulder - A joint name that represents the left shoulder.
- .leftElbow - A joint name that represents the left elbow.

.rightArm group
- .rightWrist - A joint name that represents the right wrist.
- .rightShoulder - A joint name that represents the right shoulder.
- .rightElbow - A joint name that represents the right elbow.

.leftleg group
- .leftHip - A joint name that represents the left hip.
- .leftKnee - A joint name that represents the left knee.
- .leftAnkle - A joint name that represents the left ankle.

.rightleg group
- .rightHip - A joint name that represents the right hip.
- .rightKnee - A joint name that represents the right knee.
- .rightAnkle - A joint name that represents the right ankle.

Snippet converting a 2D image to 3D world

- You need to initialize an image asset and call the request function.
- If the request function is successful, a VNHumanBodyPose3DObservation will be returned without error.
There are two ways we can retrieve position VNHumanBodyPose3DObservation:
- For accessing a specific joint's position.
`swift let recognizedPoint = try observation.recognizedPoint(.centerHead)`
- For accessing a collection of joints with a specified group name.
`swift let recognizedPoints = try observation.recognizedPoints(.torso)`
Other advantages
- bodyHeight and heightEstimation

- Understanding where the camera was relative to the person when the frame was captured.

3D Positions in Vision
- VNPoint3D is the base class that defines 4x4 matrix for storing 3D position. This notation is consistent with ARKit and available for all rotations and translations.
- VNRecognizedPoint3D is used to store corresponding information like joint name and inherits position and adds an identifier.
- VNHumanBodyRecognizedPoint3D is used to get more specifics around how to work with properties of the point like local position and the parent joint.
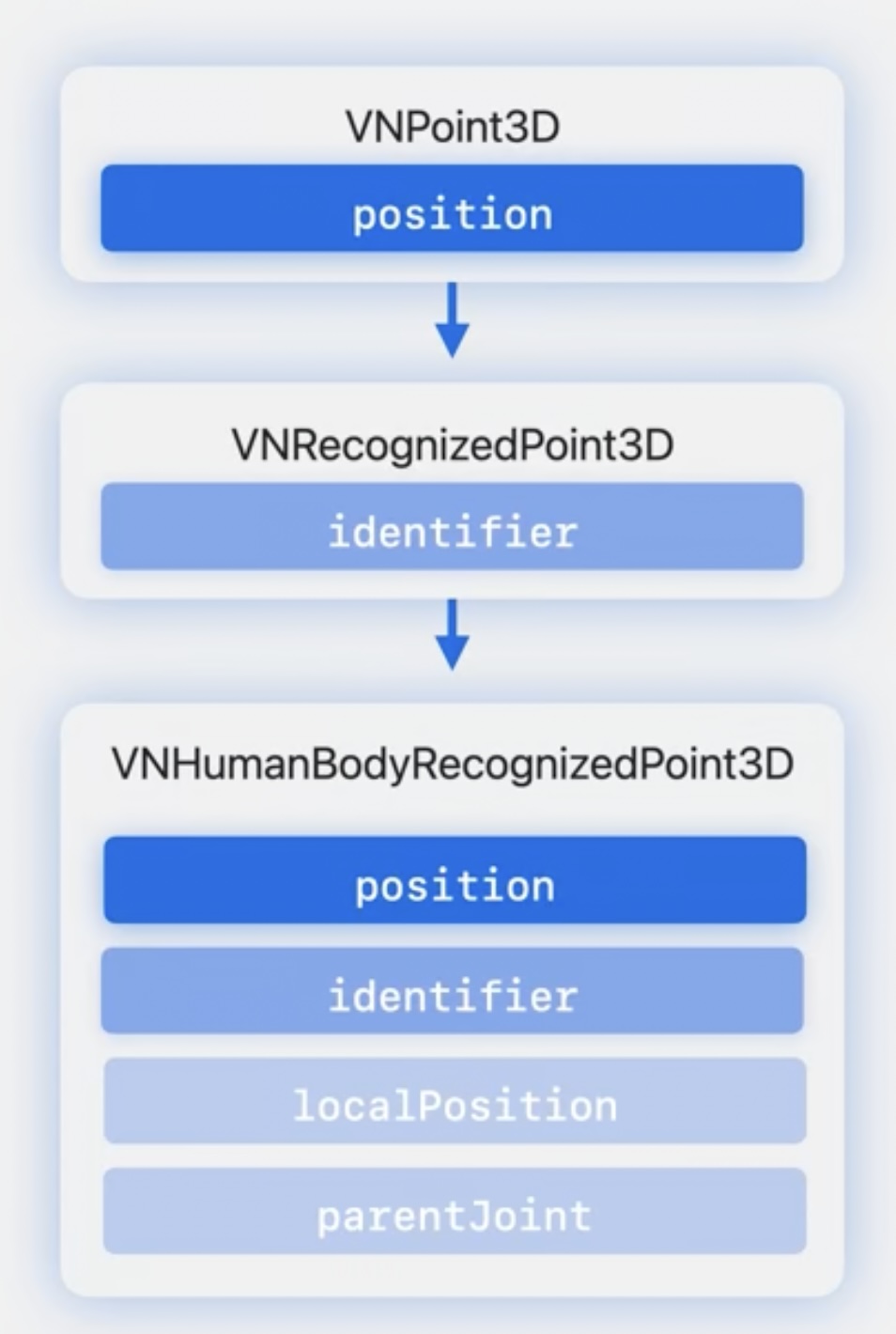
- point.position - It retrieves skeleton's root joint at the center of hip. For example: .leftWrist
- point.localPosition - It is the position relative to a parent joint. It works only one area of the body. Eg. determining the angle between child and parent joint.
`swift public func calculateLocalAngleToParent(joint: VNHumanBodyPose3DObservation.JointName) -> simd_float3 { var angleVector: simdfloat3 = simdfloat3() do { if let observation = self.humanObservation { let recognizedPoint = try observation.recognizedPoint(joint) let childPosition = recognizedPoint.localPosition let translationC = childPosition.translationVector // The rotation for x, y, z. // Rotate 90 degrees from the default orientation of the node. Add yaw and pitch, and connect the child to the parent. let pitch = (Float.pi / 2) let yaw = acos(translationC.z / simd_length(translationC)) let roll = atan2((translationC.y), (translationC.x)) angleVector = simd_float3(pitch, yaw, roll) } } catch { print("Unable to return point: (error).") } return angleVector }`
Depth in Vision
- Vision framework is now accepting depth as input along with image or frame buffer
- New API request accepting depth as parameter
`swift let requestHandler = VNImageRequestHandler(cmSampleBuffer: frameBuffer, depthData: depthData, orientation: .up, options: [:]) let requestHandler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer, depthData: depthData, orientation: .up, options: [:])` - API will fetch depth from URL
`swift let requestHandler = VNImageRequestHandler(url: imageURL)`
Working with Depth
- AVDepthData is the container class which interfaces all Depth metadata (which is captured from camera sensors).
- Depth map has either Disparity (DisparityFloat16, DisparityFloat32) or Depth format (DepthFloat16, DepthFloat32).
- Depth map data can be interchangable and converted to other format using AVFoundation.
- Depth metadata is used to construct 3D scene. Depth metadata also has camera calibration data (instrinsics, extrinsics, and lens distortion). See more in the session "Discover advancements in iOS camera capture" from WWDC22.
Sources of Depth
- Camera captured session or file.
- Images captured by camera app like portrait images, which stores dispartiy data.
- LiDAR enables high accuracy measurment of scene.
Person Instance Mask
- Vision API is now supporting when it interacts with more than one person in the image.
- Person Segmentation technique is used to separate people from the surroundings.
VNGeneratePersonSegmentationRequest
- Uses single mask for all people in the frame.


VNGeneratePersonInstanceMaskRequest
- API allows you to be more selective.
- You can select and lift the subjects other than people.
- It allows upto 4 people in foreground (individual mask)
See more in the session "Lift subjects from images in your app" from WWDC23.
Selecting personal instance mask which you want from an image
result.createMattedImage(
ofInstances: result.allInstances,
from: requestHandler,
croppedToInstancesExtent: false
)
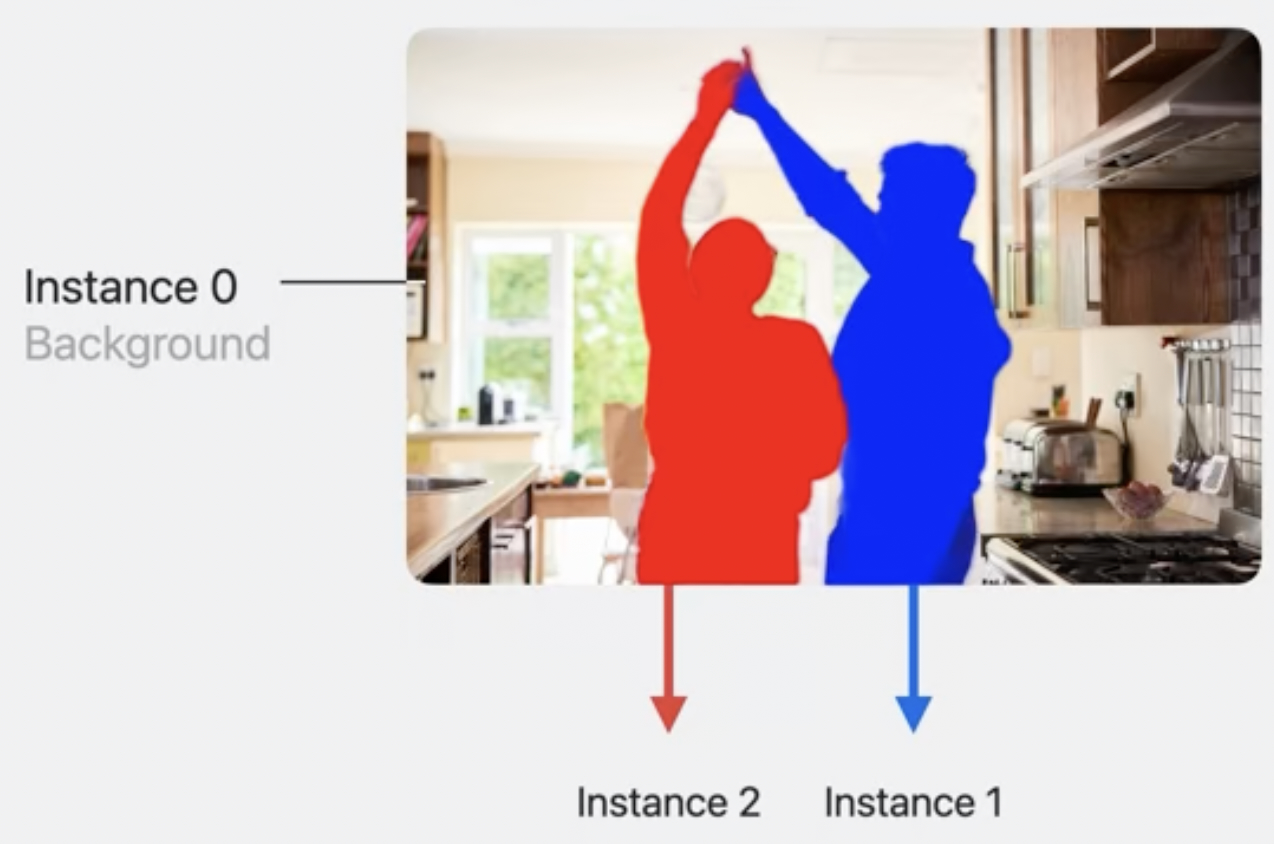
Selecting personal instance mask with many people
When more than four people are present request may be missing people in background or merge people in close contact. You can use either any one technique. - Use face detection API to filter four or more people. - Use person segmentation request and work with one mask for everyone. 
Wrap-up
- Vision framework is now offering a powerful ways to understand people, environment supporting depth, 3D Human Body Pose, and person instance masks.
Also See more in the session "Detect animal poses in Vision" from WWDC23.
 GitHub
GitHub