Customize on-device speech recognition
 Travis Ma
Travis Ma
Description: Find out how you can improve on-device speech recognition in your app by customizing the underlying model with additional vocabulary. We'll share how speech recognition works on device and show you how to boost specific words and phrases for more predictable transcription. Learn how you can provide specific pronunciations for words and use template support to quickly generate a full set of custom phrases — all at runtime. For more on the Speech framework, check out “Advances in Speech Recognition” from WWDC19.
Previous Iteration of Speech Recognizer
By default, when you embed Apple's Speech framework into your app it uses a general language model to reject transcription candidates that it feels are less likely. This doesn't work well if your app is geared toward less common verbiage.
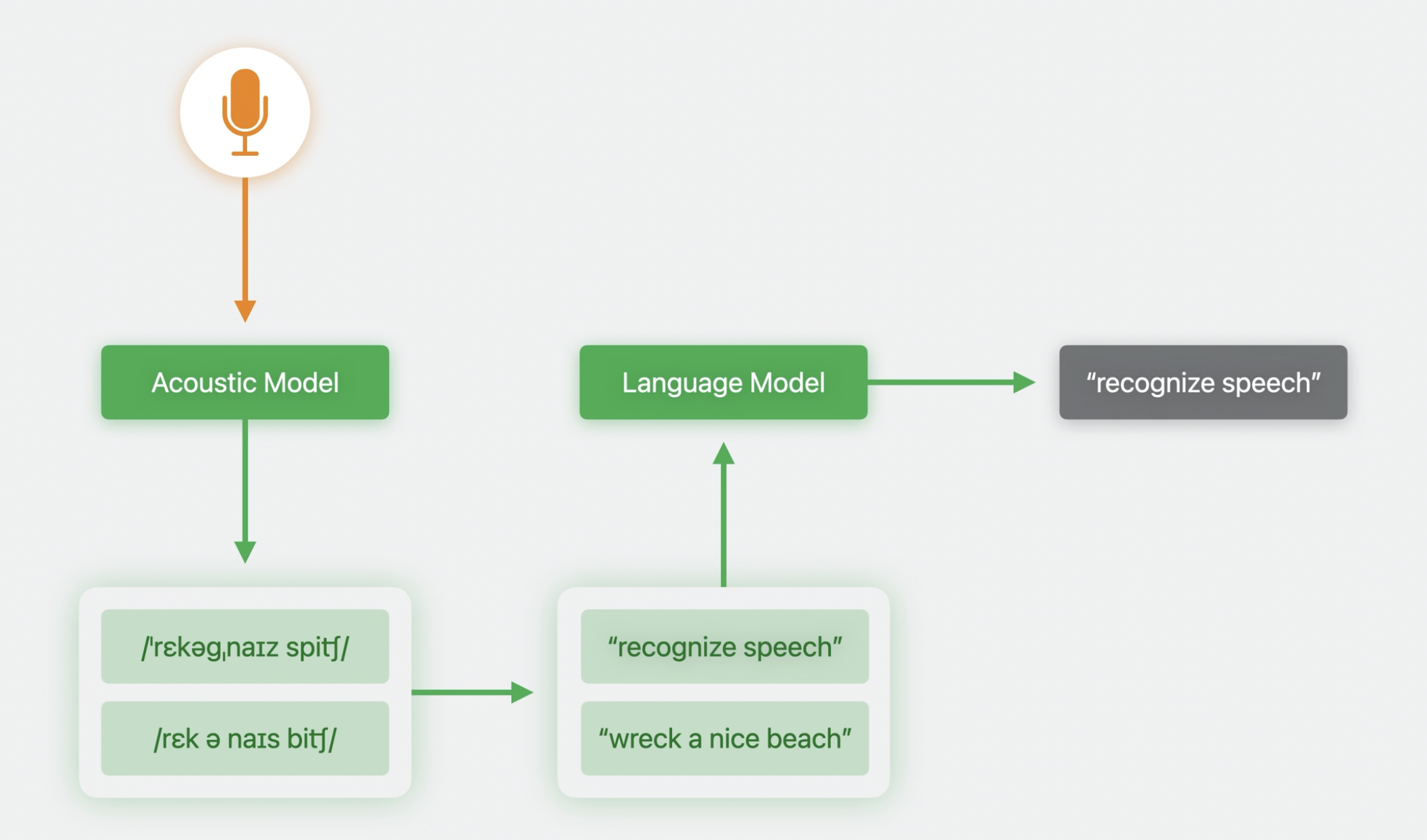
For example, in a chess app, you may want to tell the app "Play the Albin counter gambit" but this verbiage is so rare in the general language model that it incorrectly interprets this as "Play the album Counter Gambit".
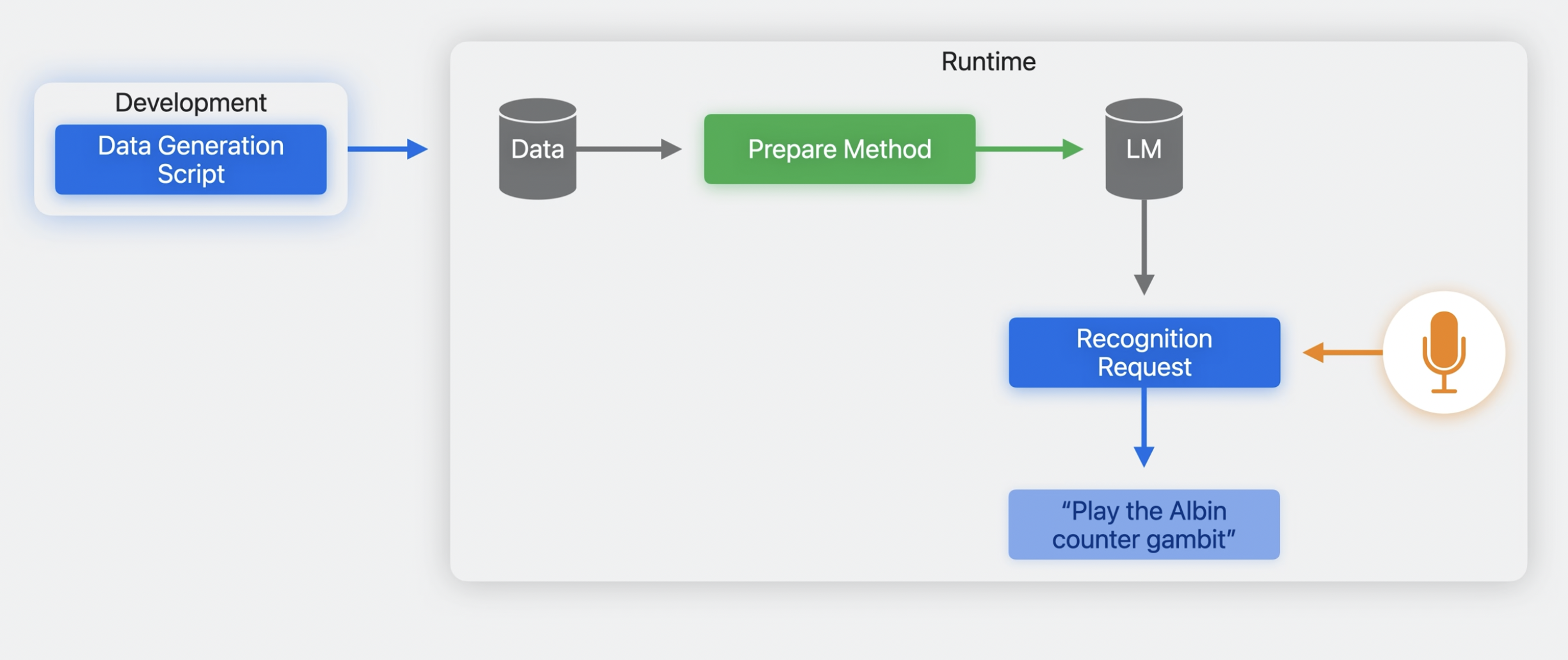
Language Model Customization
New in iOS 17, you'll be able to customize the behavior of the SFSpeechRecognizer's language model, tailor it to your application, and improve its accuracy.
Steps: 1. Create a collection of training data (during development process) 1. Prepare the training data 1. Configure a recognition request 1. Run it
Data Generation
Training data will consist of bits of text that represent phrases your app's users are likely to speak.
import Speech
let data = SFCustomLanguageModelData(
locale: Locale(identifier: "en_US"),
identifier: "com.apple.SampleApp",
version: "1.0"
) {
SFCustomLanguageModelData.PhraseCount(
phrase: "Play the Albin counter gambit",
count: 10
)
}
In the above example, we feed our custom phrase into the model 10 times. Experiment often, you could be surpised at how quickly the model learns your phrases.
Only so much data can be accepted by the system, so balance your need to boost phrases against your overall training data budget.
Furthermore, you can declare classes of words and put them into a pattern to represent every possible combination.
SFCustomLanguageModelData.PhraseCountsFromTemplates(
classes: [
"piece" : ["pawn", "rook", "knight", "bishop", "queen", "king"],
"royal" : ["queen", "king"],
"rank" : Array(1...8).map({String($0)})
]
) {
SFCustomLanguageModelData.TemplatePhraseCountGenerator.Template(
"‹piece> to <royal> <piece> <rank>",
count: 10000
)
}
When you are done building up the data object, export it to a file and deploy into your app like any other asset.
try await data.export(to: URL(filePath: "/var/tmp/SampleApp.bin"))
If your app makes use of specialized terminology, for example, a medical app that includes the names of pharmaceuticals, you can define both the spelling and pronunciations of those terms, and provide phrase counts that demonstrates their usage.
- Pronunciations are accepted in the form of X-SAMPA strings
- Each locale supports a unique subset of pronunciation symbols
SFCustomLanguageModelData.CustomPronunciation(
grapheme: "Winawer",
phonemes: ["w I n aU @r"]
)
SFCustomLanguageModelData.PhraseCount(
phrase: "Play the Winawer variation",
count: 10
)
The model can also be trained at runtime, for example, if you want to train it on commonly used names from the user's contacts.
func scrapeDataForLmCustomization() {
Task.detached {
let data = SFCustomLanguageModelData(
locale: Locale(identifier: "en_US"),
identifier: "SampleApp",
version: "1.0"
) {
for (name, timesCalled) in getCallHistory() {
SFCustomLanguageModelData.PhraseCount (
phrase: "Call \(name)",
count: timesCalled
)
}
//...
}
}
}
Once the training data is generated, it is bound to a single locale. If you want to support multiple locales within a single script, you can use standard localization facilities like NSLocalizedString to do so.
Deploying Your Model
public func prepCustomlm() {
self.customLmTask = Task.detached {
self.hasBuiltLm = false
try await SFSpeechLanguageModel.prepareCustomLanguageModel(
for: self.assetPath,
clientIdentifier: "com.apple.SampleApp",
configuration: self.ImConfiguration
)
self.hasBuiltLm = true
}
}
This method call can have a large amount of associated latency, so it's best to call it off the main thread, and hide the latency behind some UI, such as a loading screen.
public func startRecording(updateRecognitionText: @escaping (String) -> Void) throws {
recognitionRequest = SFSpeechAudioBufferRecognitionRequest ()
// keep recognition data on device
recognitionRequest.requires0nDeviceRecognition = true
recognitionRequest. customizedLanguageModel = self.ImConfiguration
//...
}
When your app constructs the speech recognition request, you first enforce that the recognition is run on device. Failing to do so will cause requests to be serviced without customization.
 GitHub
GitHub
 www.travisma.me
www.travisma.me