Understanding Images in Vision Framework
 Federico Zanetello
Federico Zanetello
Description: Learn all about the many advances in the Vision Framework including effortless image classification, image saliency, determining image similarity, and improvements in facial feature detection, and face capture quality scoring. This packed session will show you how easy it is to bring powerful computer vision techniques to your apps.
Image Saliency
Saliency = Most noticeable or important
Vision offers two types of Saliency:
- Attention Based: Based on humans, creating a heat map on the image guessing where we, humans, will look first.
- Objectness Based: Creates a heatmap with the goal to highlight the foreground objects or the subjects of an image.

| Original Image | Attention Based Saliency | Objectness Based Saliency |
Attention Based Saliency is the hardest one, because it involves many factors including: contrast, faces, subjects, horizons, light, perceived motion, ...
How’s it done?
The heat map is requested via a VNImageRequestHandler where we will perform a attention/objectness based request, which will return an optional heat map made of floats from 0 (non salient) to 1 (max saliency), this map is smaller than our original pic so we will need to scale in order to obtain the effect in the images above.
Beside the heatmap, vision gives us also a bounding box which encapsulates the saliency area:

Attention based saliency will always have up to 1 bounding box, while objectless based saliency will have up to 3 bounding boxes.
The bounding boxes are normalized and respect the image dimensions.
(This is awesome when showing a thumbnail of an image.)
Image Classification
Over one thousand of objects recognizable.
The classification is based on Taxonomy, which is a hierarchical structure:
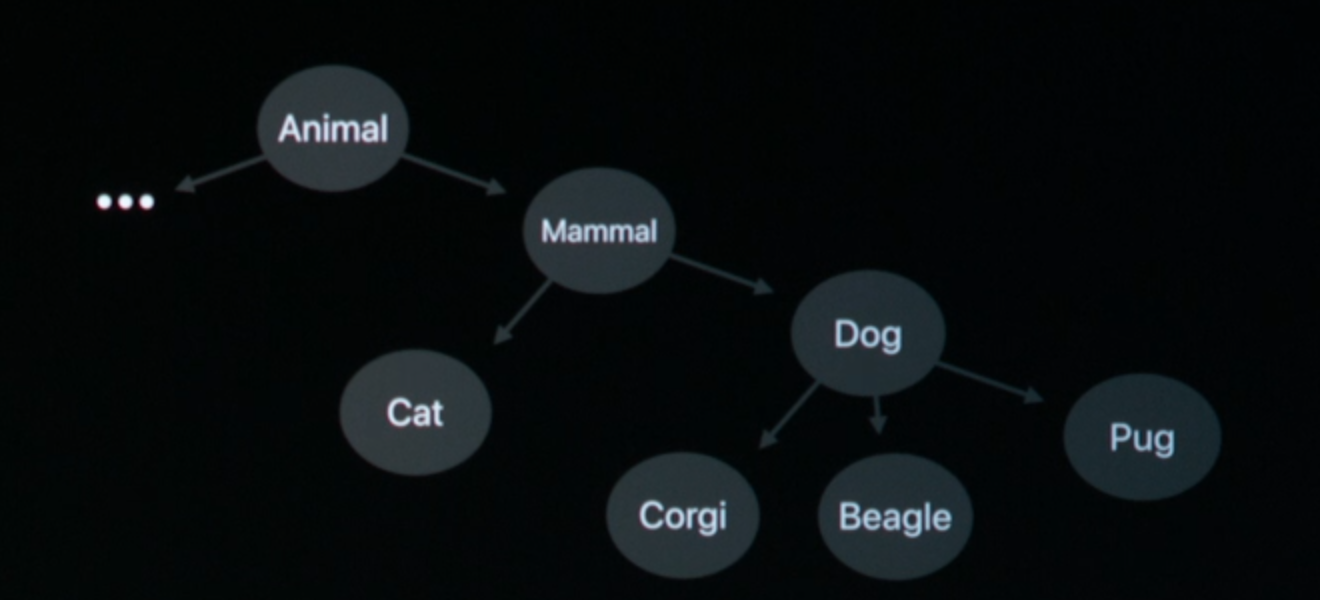
How’s it done?
Like before, in order to get a classification we need a VNImageRequestHandler and submit a VNClassifyRequest.
This request will give us back an array of observations, each observation will have a label and a confidence. E.g. (animal, 0.8), (cat, 0.75), (hat, 0.8)
Beside confidence, each class has a recall and precision value, both of which differ between different objects types (classes).
We can use these values, along with the confidence value, to more securely filter the results of our classification.
These values are very powerful as they’re custom for each object kind.
Based on our images, we can tweak these values in order to not return too few matches, or not too many false positives.
Image Similarity
In short, each image has a FeaturePrint (computed via saliency and more), which is an image descriptor similar to a word vector (obtained via classification).
Similarity is a number (actually, a vector distance): the smaller it is, the more similar the images are.

Cats pics are more similar than a crocodile pics.
Face Technology
Previously we only had one confidence score, now we have one for each face feature. Speaking of features, we now have 76 points/feature, while previously we only had 65. This means that we can now recognize more precisely different faces (think of twins etc).
Pupil detection is much better.
New people and pet detector. returns bounding boxes of the human (torso area), or the pet, along with a label describing which animal.
Improved Vision tracking.
In all Machine Learning sessions Apple is making available to developers tools that Apple has been using in the previous years. If you think about it, you will find an use of each Machine Learning feature in Apple’s stock apps.
For example: Saliency is one of the most important pillars to make the photos.app smart:
- Given an image
- Detect the important areas via saliency bounding boxes
- Crop bounding boxes and run them on vision to categorize the original pic.

 GitHub
GitHub
 zntfdr.dev
zntfdr.dev